El machine learning (aprendizaje automático) es una rama de la inteligencia artificial que se enfoca en desarrollar algoritmos y modelos que pueden aprender de los datos y mejorar su rendimiento en tareas específicas sin ser explícitamente programados. Para conseguirlo, en lugar de seguir reglas predefinidas, los algoritmos de aprendizaje automático pueden analizar y aprender patrones y relaciones en los datos, lo que les permite emitir predicciones, tomar decisiones o realizar tareas complejas.
En la actualidad los modelos de aprendizaje automático se han convertido en un recurso tecnológico implementado en herramientas de uso diario como filtros anti-spam para correos electrónicos, conducción automática de coches o softwares de reconocimiento de voz.
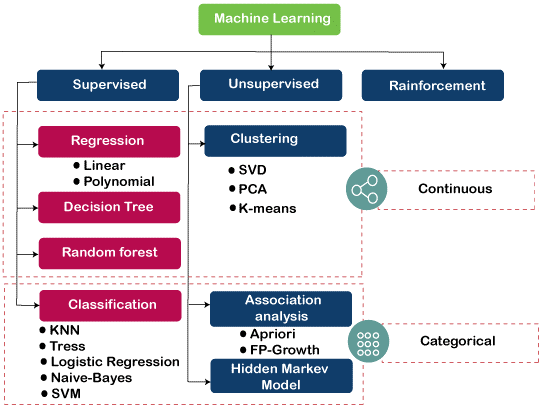
Dentro de este campo de desarrollo tecnológico en plena expansión existen diferentes tipos de aprendizaje automático. Veamos a continuación de qué tratan.
Aprendizaje supervisado
El aprendizaje supervisado es un tipo de aprendizaje automático en el que la máquina necesita supervisión externa para aprender. Los modelos de aprendizaje supervisado se entrenan utilizando el conjunto de datos de entrenamiento. Una vez terminado, se prueba el modelo proporcionando datos de prueba para verificar si predice el resultado correcto.
Gracias al aprendizaje desarrollado por estos modelos supervisados se alimenta un conjunto de resultados que permite realizar predicciones adecuadas del comportamiento de datos nuevos que aún no han sido procesados. Este tipo de aprendizaje es el que se incorpora en aplicaciones tecnológicas como filtros detectores de spam en correos electrónicos, detectores de imágenes en captchas o en aplicaciones de reconocimiento de voz o escritura.
El aprendizaje supervisado se emplea para dos tipos de problemas:
- Clasificación
- Regresión
Los problemas de regresión son aquellos en los que se busca encontrar un modelo capaz de predecir un valor numérico continuo como resultado en función de los valores de un conjunto de características de entrada. Estos son empleados en diversas áreas, como la predicción de precios, la estimación de ingresos, el pronóstico del clima y muchas otras aplicaciones.
En los problemas de clasificación el objetivo es establecer un modelo capaz de clasificar elementos nuevos y desconocidos dentro de una serie de categorías ya establecidas en base a sus características. Los modelos de clasificación se aplican en una amplia gama de áreas, como detección de fraudes, reconocimiento de imágenes, diagnóstico médico, análisis de sentimientos, entre otros. Algunos ejemplos de algoritmos populares de aprendizaje supervisado son la regresión lineal simple, el árbol de decisión, la regresión logística, el algoritmo KNN.
Aprendizaje no supervisado
Es un tipo de aprendizaje automático en el que la máquina no necesita ninguna supervisión externa para aprender de los datos, por lo que se denomina aprendizaje no supervisado.
Los modelos no supervisados se pueden entrenar utilizando el conjunto de datos sin etiquetar que no está clasificado ni categorizado, y el algoritmo debe actuar sobre esos datos sin ninguna supervisión.
En el aprendizaje no supervisado, el modelo no tiene una salida predefinida e intenta encontrar información útil a partir de la gran cantidad de datos. Estos se utilizan para resolver principalmente dos tipos de problemas:
- Agrupación ( clusterización )
- Asociación
Los problemas de agrupación, también conocidos como problemas de clusterización, son un tipo de problema donde el objetivo es agrupar un conjunto de elementos similares en grupos o clústeres en base a la similitud de sus características. Para ello, el modelo busca formar grupos de elementos que sean similares entre sí y diferentes de las instancias en otros grupos. Estos modelos se emplean es descubrir estructuras ocultas o patrones emergentes en los datos sin la necesidad de tener información de las clases de antemano.
Es preciso diferenciar los problemas de agrupación de los de clasificación. A diferencia de los últimos; en los problemas de agrupación las categorías no están definidas inicialmente, sino que es el modelo quien debe establecerlas.
Por otro lado, los problemas de asociación se centran en descubrir patrones y relaciones entre diferentes elementos que ocurren juntos con una alta frecuencia o que están asociados de alguna manera dentro de un conjunto de datos. Estos modelos son utilizados en el análisis de mercado, la recomendación de productos y la minería de datos para tomar decisiones basadas en patrones de ocurrencia y preferencias de los usuarios.
Aprendizaje reforzado
En el aprendizaje por refuerzo, un modelo es puesto a prueba realizando una serie de tareas en base a cuyo éxito o fracaso el modelo es perfeccionado mediante retroalimentación. Esta retroalimentación tiene la forma de recompensas, tal que, por cada éxito se facilita una respuesta positiva, mientras que por cada fracaso recibe una respuesta negativa.
El aprendizaje reforzado se aplica en una amplia gama de dominios, como robótica, juegos, optimización de recursos, gestión de inventarios, control de procesos, entre otros. Por ejemplo, se ha utilizado para entrenar agentes que pueden jugar juegos de mesa como Go y ajedrez a un nivel sobrehumano, así como para optimizar la gestión de energía en edificios inteligentes.
Algoritmos del Machine Learning
Para la implementación de los diferentes modelos vistos se emplean una serie de algoritmos capaces de aprender e identificar patrones:
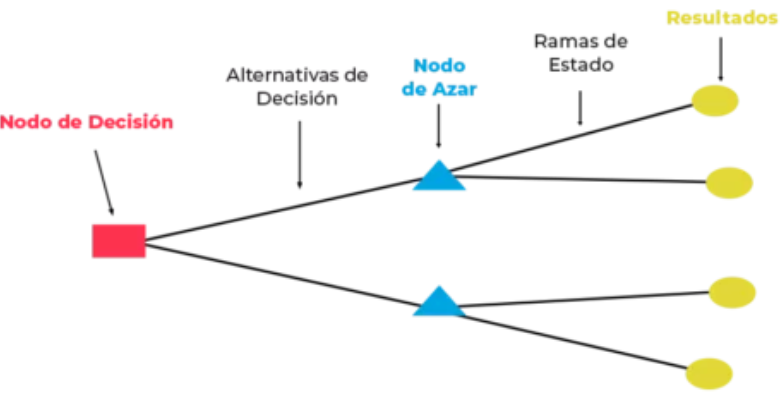
- Arboles de decisión -> Es un algoritmo que representa todos los posibles resultados de un proceso en función de una serie de nodos interconectados que representan diferentes decisiones y sus posibles resultados.
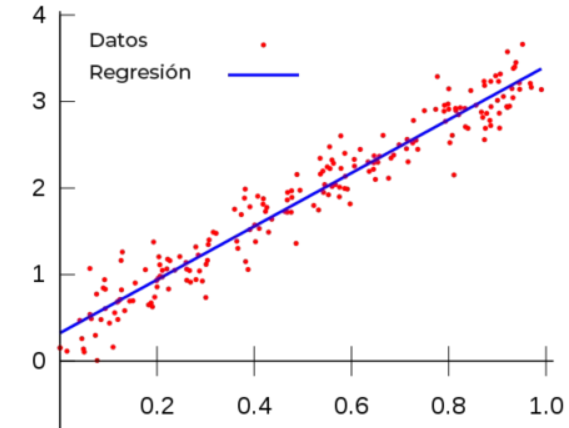
- Algoritmos de regresión -> Son algoritmos que reconocen patrones de tendencias presentes en secuencias de valores de entradas.
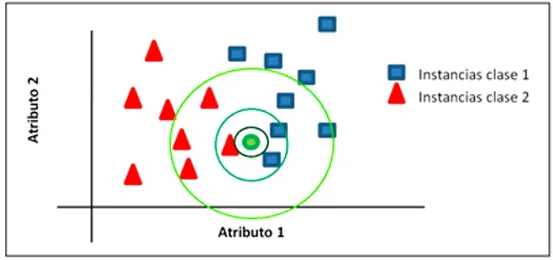
- Algoritmos basados en instancias -> Son algoritmos que clasifican conjuntos de elementos que guardan semejanza en base a una serie de atributos o características.
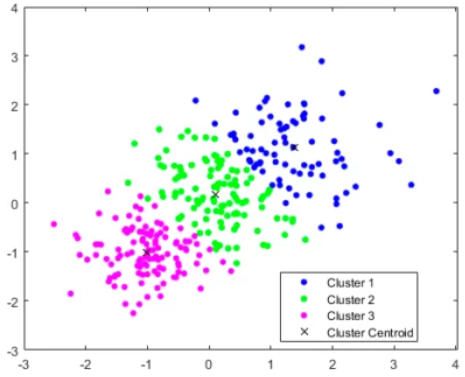
- Algoritmos de agrupamiento ( clusterización ) -> Estos algoritmos se centran en el agrupamiento de datos no etiquetados para generar grupos ( clusters ).
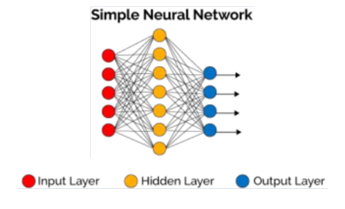
- Algoritmos de redes neuronales -> Son algoritmos que emulan el funcionamiento del cerebro procesando los datos mediante conjuntos de neuronas artificiales interconectadas formando diferentes capas y arquitecturas.
Existen multitud de tipos de redes neuronales centradas en el reconocimiento de patrones.